레거시 코드에서 csv 를 생성해주는 코드(csv 다운로드 기능)가 여러 이유로 아직도 쓰이고 있다.
로직은 xlsx 를 생성하고 이 xlsx 로부터 데이터를 읽으며 csv 를 쓰는 로직이었다.
오래된 코드(무려 2013년!)이고, 다 퇴사를 해버린데다 히스토리 관리가 잘 안 돼있어서 왜 xlsx 를 먼저 생성하는지 정확한 이유를 찾진 못했지만, 이미 xlsx 다운로드 기능을 먼저 만들어놔서 그것을 활용하는 게 더 낫다고 판단이 됐었나 보다.
그러던 중, 어제 약 23,000 rows 에 대한 csv 다운로드 요청이 OOM 을 유발하며 서버가 죽는 현상이 발견되었다. (컬럼수도 493개였음)
xlsx 를 생성할 때 Workbook 의 인스턴스 타입을 XSSFWorkbook 으로 되어있었는데, 해당 인스턴스는 row 쓰기를 할 때 메모리를 비우지 않는다. 그래서 속도가 느리고, 큰 데이터를 다룰 땐 OOM 을 맞을 수 있다.
그런데 csv 기능 이전에 만들었을 것으로 추정되는 xlsx 다운로드 기능에서는 SXSSFWorkbook 인스턴스 타입으로 코딩이 되어 있었다.
왜 늦게 생긴 csv 생성 로직에는 오히려 XSSFWorkbook 을 쓰게 되었나 궁금해서 코드를 뒤져보니, 생성한 xlsx Workbook 으로부터 데이터를 읽어야 했기 때문으로 생각이 되었다.
그래서 SXSSFWorkbook 으로 변경을 해줬는데,
Sheet = workbook.getSheet(0);
Row row = sheet.getRow(1); // getRow(1) -> null와 같은 코드에서 NPE가 발생하는 것이었다.
그 이유를 찾아보니 SXSSFWorkbook 은 쓰기전용이라는 것을 알게 되었다.
https://bz.apache.org/bugzilla/show_bug.cgi?id=54743
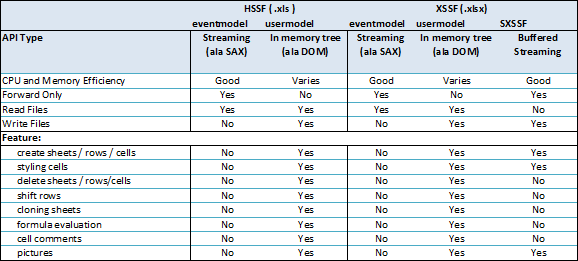
그렇다고 유지보수가 안 된 옛날 코드를 SAX 를 쓰도록 재작성 할 수도 없고(곧 버려질 코드) 해서, 아래와 같이 읽기 가능한 Workbook 으로 변환을 하여, 쓰기와 읽기 용도에 맞게 인스턴스 타입이 사용되도록 하니, "쓰기 속도 향상 + OOM 이슈 없음" 을 얻음과 동시에 기존 로직에 영향이 없도록 작업을 마칠 수 있었다.
// ...
private static void convertXLStoCSV(BufferedWriter bw, SurveyVO survey, Workbook writeOnlyWb) {
// ...
Workbook readableWb = getReadableWbFromWriteOnlyWb(writeOnlyWb);
Sheet sheet = readableWb.getSheetAt(0);
Iterator<Cell> typeIterator = sheet.getRow(1).cellIterator(); // 더 이상 NPE 발생하지 않음!
// ...
}
// ...
private static Workbook getReadableWbFromWriteOnlyWb(SXSSFWorkbook writeOnlyWb) throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
writeOnlyWb.write(bos);
byte[] bytes = bos.toByteArray();
InputStream is = new ByteArrayInputStream(bytes);
return new XSSFWorkbook(is);
}

