부제 : findAndModify 를 이용한 auto_increment 구현 시, 성능을 고려한 설계 필요
서론
작년(2021년) 이맘때 쯤, 회사에서 서비스하고 있는 리멤버의 알림 서비스/도메인을 분리하는 프로젝트를 진행했었다.
Java 기반의 알림 서비스로 MSA 전환기 - 리멤버 기술 블로그
Java 기반의 알림 서비스로 MSA 전환기 - DRAMA&COMPANY
안녕하세요! 리멤버에서 Platform Crew에 속해있는 서버 개발자 신선영입니다. 플랫폼 크루에서는 기존의 Ruby로 만들어진 모놀리틱 서비스를 점진적으로 Java 기반의 MSA로 전환하는 작업을 하고 있
blog.dramancompany.com
대부분의 설계, 작업은 다른 분들이 하셨었고 나는 주로 설계 리뷰, 코드 리뷰에 참여하여 함께 작업을 진행했었는데, 약 1년이 지난 지금을 기준으로 약 1년간 함께 운영해보며 겪은 것들에 대해 기록해보고자 한다.
MongoSocketReadTimeoutException 의 발생

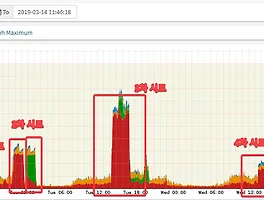
위 스크린샷과 같이 간헐적으로 MongoSocketReadTimeoutException 이 발생했다.
이 사실을 올해 7월 말에 발견하였었는데, 그 이전에도 계속 발생했을 것이다. (로그 리텐션 기간 때문에 지금은 정확히 언제부터 발생했는지 파악이 어렵다.)
당시 Root cause 를 찾진 못했고, 간헐적으로 적은 빈도로 발생하는 것이었기에 아래와 같이 MongoDB 커넥션의 read socket timeout 을 조정하는 것을 통해 해결하고자 했었다.

이 때 read socket timeout 을 조정하니 MongoSocketReadTimeoutException 의 발생빈도가 줄어들었으나 여전히 발생은 하고 있었다. 이 글을 쓰는 지금 돌이켜보면, 이 때 충분히 root cause 를 파악하는 데 시간을 들였다면 좋았을텐데 그러지 못했던 것이 아쉽다.
Index Size 에 맞는 CPU, Memory 재배치 (via modifing documentDB's instance class)
약 2달 반전(2022-10-08)에 count operation 을 실행할 때 성능 이슈가 발생했음을 인지했다.
그리고 여전히 MongoSocketReadTimeoutException 가 과거에 발생하던 것보다 훨씬 많이 발생하고 있음을 발견하였다.



이런 패턴의 상황이 생겼을 때는 단순한 find operation 도 12초가 걸리는 등 심각한 상황이었다.
주어진 정보들을 가지고 여러 가설들을 세워보았고, 그 중 index size 와 documentDB 에 할당된 메모리의 상관관계가 가장 유력한 원인이었을 것이라는 판단을 했고,

documentDB 에 할당된 메모리는 32GB 였는데, 알림 데이터를 위해 생성해둔 인덱스의 총 사이즈(totalIndexSize)가 44GB 가 넘는 것을 확인하였다.
index 를 메모리에 올려놓는 documentDB 의 특성에 따라 이것으로 인한 것이라는 것에 확신이 들었고, instance class 를 1단계 더 큰 것(mem 64GB)으로 교체를 진행했고 이 이슈는 해결이 됐다.
findAndModify 의 성능 이슈 발견 및 해결
작년에 알림 도메인을 분리하면서, 기존의 RDB 에서 채택했던 설계에 따라 저장된 알림 데이터들을 AWS documentDB 로 이전함에 따라 기존 데이터를 마이그레이션 해줘야 했고 클라이언트의 하위호환 이슈 때문에 RDB 의 auto_increment 와 같은 순차적으로 증가하는 Primary Key 를 사용하는 것을 유지하기로 했었다.
하지만 documentDB 의 자체적인 기능으로는 auto_increment 필드라는 개념이 없었기 때문에 workaround 를 찾아야 했다. 다행히 알려진 workaround 들이 몇개가 있었다.
1. findAndModify 를 이용한 방법 : MongoDB Auto-Increment - 이 방법이 가장 잘 알려져있고 많이 쓰이고 있다.
MongoDB Auto-Increment
Learn how to implement auto-incremented fields with MongoDB Atlas triggers following these simple steps.
www.mongodb.com
2. 채번용으로만 RDB 의 auto_increment 를 이용하기
3. 가장 마지막으로 insert 된 ID(sequence) 값을 읽어서 +1 해주는 loop 를 이용하기
작년에 작업하던 당시에는 findAndModify 를 이용하기로 했었고, 모든 유저의 모든 알림에 대해서 똑같은 counter 용의 document 1개를 저장해두고 이를 사용하도록 설계/구현됐다.
그러나 시간이 지날수록 타 서비스들에서 알림을 생성하는 요청의 패턴에 변화가 생기면서 throughput 이 늘어남에 따라 아래와 같은 성능 이슈가 드러나기 시작했다.
사실, 이 이슈도 오래전부터 발생했을텐데 그동안 큰 문제라고 인식을 하지 않은 상태에서 `알림 저장 throughput 을 늘리기 위한 태스크` 를 따로 진행하려던 와중에 다시 이슈를 보면서 문제로 인식을 하게 된 케이스이다.

findAndModify operation 하나의 avg duration 이 350ms 까지나 되다니! 이건 심각한 문제였고, 우리가 documentDB 를 잘 사용하지 않고 있다는 것을 반증하는 지표였다.
이 이슈에 대해서도 여러가지 관점에서의 다양한 가설들을 세운 후, 운영환경으로부터 격리되고 독립된 환경에서 많은 실험들을 진행하며 원인을 규명해갔다.
처음에는 DBCP 의 설정이 잘못돼있는 것이란 가설을 세웠고 이에 대해 많은 실험을 진행했으나 DBCP 라는 변수에 의한 성능에의 영향은 크지 않았음을 확인했고, 아래와 같은 가설&문제 해결 방안을 떠올려보았다.

저때, `t3, t4g 타입으로 변경` 이 최고의 옵션이라고 생각하긴 했으나 지금 생각해보면 최고의 옵션은 아니었지만 특정한 시간대에 spike 가 몰리는 우리 서비스 특성을 고려하면 현재도 유효한 옵션이긴 하나 cpu, mem 이 한참 모자란 medium 만 지원하고 있기 때문에 아쉽다.
결론적으로는 `notificationID 획득 방법/저장 구조 변경` 을 진행하여 문제가 해결됐다.
기존에는 단 1개의 counter 에 대해서 findAndModify 가 발생하였고, 이 때문에 그 1개 document 에 대한 update 시도에 따른 lock 이 많이 발생하다 보니 성능 이슈가 생겼던 것이었다.
다행스럽게도 기존에 짜여진 API 스펙, 코드들이 저장 구조 변경하는 작업을 쉽게 할 수 있도록 돼있었다.
알림 데이터 특성상, 사용자가 다른 사람의 알림을 볼 수는 없게 돼있기 때문에 사용자 별로 따로 counter document 를 두고, 그것으로부터 auto increment 한 ID 값을 채번하기 위해 findAndModify 가 일어나도록 한다면 1개 document 에 대한 update 요청이 수백만개의 document 에 대한 update 로 분산이 되기 때문에 문제가 해결이 될 것이란 예상을 하였고 이 작업을 하고 배포하니 예상대로 해결이 됐다. 이 작업을 하는 과정에서 `notificationId` 단일 필드에 대한 unique index 를 제거할 수도 있어서 index 용량 확보도 이뤄졌다.
글을 쓰고 있는 지금은 traffic spike 상황이 생겨도 findAndModify operation 의 peak duration 이 12ms 내외로 양호한 수준을 유지하고 있다.

또한 이 문제가 해결됨으로써 별도로 진행하고자 했던 `알림 저장 throughput 을 늘리기 위한 태스크` 도 자연스럽게 별도의 작업을 진행하지 않아도 됐고 충분한 throughput 이 확보됐다.
결론 (회고)
작년에 알림 서비스를 분리하기 전에는 MongoDB(~DocumentDB)에 대해 아는 바가 거의 없는 상태였다. 가끔 디버깅을 하다가 이미 누군가 예전에 구축해둔 MongoDB 와 관련하여 파악할 필요가 있을 때 정도만 필요한 지식들을 찾아가며 건드려본 게 거의 전부였다.
알림 서비스를 분리하면서 이론적으로 알고 있는 지식에 따라 MonogoDB 를 채택하였다. 팀 내에 실질적인 경험이 있는 분이 없는 상태에서의 기술을 도입하는 것이어서 불안한 마음이 적지 않았었다. 그래도 분리 작업을 할 당시에 이론적인 지식을 많이 채워가면서 진행하다보니 MongoDB 를 채택한 것이 잘 한 결정이라는 확신이 들기 시작했다.
또한 얼마전에 올라온 LINE 알림 센터의 메인 스토리지를 Redis에서 MongoDB로 전환하기 글에서도 볼 수 있듯이 나와 우리 팀이 했던 고민과 그 고민에 따른 설계를 거의 그대로 한 것을 보니 잘 한 판단이라고 스스로 평가할 수 있다. :D - 사용자 스토리가 우리랑은 달랐기 때문에 LINE 에서의 고민이 조금 더 깊고 넓었던 것 같긴 하다.
1년 동안 운영하며 이 글에 언급하지 않은 작은 이슈들부터 이 글에 언급된 큰 이슈들까지 꽤 많은 운영 경험이 생긴 것 같아 기쁘다. 앞으로 또 어떤 성능 문제가 있을 지 모르겠지만 어떻게든 해결할 수 있을 것이라는 자신감이 생겼고 혼자 진행한 것이 아니라 함께 도와준 동료들이 있었기에 가능했던 것이기도 해서 여러모로 나와 내 팀은 잘 성장하고 있다고 느낀다.
끝!